objectLogitRegression{ defmain(args: Array[String]): Unit = { val dataS = scala.io.Source.fromFile("D:/data/iris.csv").getLines().toSeq.tail .map{_.split(",").filter(_.length() > 0).map(_.toDouble)} .toArray val data = BDM(dataS:_*)
val features = data(0 to 98, 0 to 3) val labels = data(0 to 98, 4)
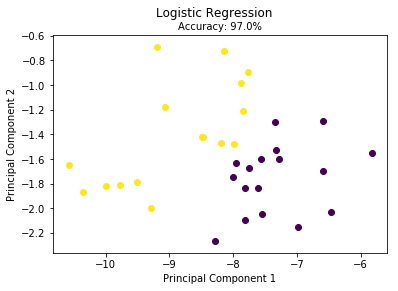
val model = newLogitRegression val w = model.fit(features,labels) val predictions = model.predict(w, features) val predictionsNlabels = predictions.toArray.zip(labels.toArray) val rate = predictionsNlabels.filter(f => f._1==f._2).length.toDouble/predictionsNlabels.length.toDouble println("正确率为:" + rate) } }
classLogitRegression (var lr: Double = 0.01, var tolerance: Double = 1e-6, var num_iters: Int = 1000) {
deffit(x: BDM[Double], y_train: BDV[Double]): BDV[Double] = { val ones = BDM.ones[Double](x.rows, 1) val x_train = BDM.horzcat(ones, x) val n_samples = x_train.rows val n_features = x_train.cols var weights = BDV.ones[Double](n_features) :* .01// 注意是:*
val loss_lst: ArrayBuffer[Double] = newArrayBuffer[Double]() loss_lst.append(0.0)
var flag = true for (i <- 0 to num_iters if flag) { val raw_output = (x_train * weights).map(sigmoid(_)) val error = raw_output - y_train val loss: Double = error.t * error val delta_loss = loss - loss_lst.apply(loss_lst.size - 1) loss_lst.append(loss) if (scala.math.abs(delta_loss) < tolerance) { flag = false } else { val gradient = (error.t * x_train) :/ n_samples.toDouble weights = weights - (gradient :* lr).t } } weights }
import numpy as np from sklearn import datasets import os import sys sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) from utils import train_test_split, accuracy_score from utils import Plot
objectsoftMax{ defmain(args: Array[String]): Unit = { val dataS = scala.io.Source.fromFile("D:/data/iris.csv").getLines().toSeq.tail .map { _.split(",").filter(_.length() > 0).map(_.toDouble) } .toArray val data = BDM(dataS: _*) val features = data(::, 0 to 3) val labels = data(::, 4)
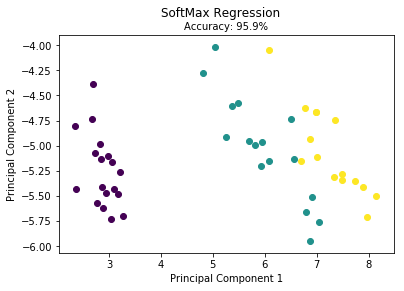
val soft = newSoftMaxRegression() val w = soft.fit(features, labels) println(w) val predictions = soft.predict(w, features) val predictionsNlabels = predictions.toArray.zip(labels.toArray) val rate = predictionsNlabels.filter(f => f._1==f._2).length.toDouble/predictionsNlabels.length.toDouble println("正确率为:" + rate) // 正确率为0.9664
} }
classSoftMaxRegression(var lr: Double = 0.01, var tolerance: Double = 1e-6, var num_iters: Int = 1000) {
deffit(x: BDM[Double], y: BDV[Double]): BDM[Double] = { val ones = BDM.ones[Double](x.rows, 1) val x_train = BDM.horzcat(ones, x)
val ncol = x_train.cols val nclasses = y.toArray.distinct.length var weights = BDM.ones[Double](ncol, nclasses) :* 1.0 / nclasses val n_samples = x_train.rows
for (iterations <- 0 to num_iters) { val logits = x_train * weights val probs = softmax(logits) val y_one_hot = one_hot(y) // val loss = sum(y_one_hot :* log(probs)) /n_samples.toDouble val error: BDM[Double] = probs - y_one_hot val gradients = (x_train.t * error) :/ n_samples.toDouble
weights -= gradients :* lr } weights }
defsoftmax(logits: BDM[Double]): BDM[Double] = { val scores = exp(logits) val divisor = sum(scores(*, ::)) for (i <- 0 to scores.cols - 1) { scores(::, i) := scores(::, i) :/ divisor } scores }
defone_hot(y: BDV[Double]): BDM[Double] = { val n_samples = y.length val n_classes = y.toArray.toSet.size val one_hot = Array.ofDim[Double](n_samples, n_classes) for (i <- 0 to n_samples - 1) { one_hot(i)(y(i).toInt) = 1.0 } BDM(one_hot: _*) }
defpredict(weights: BDM[Double], x: BDM[Double]): BDV[Int] = { val ones = BDM.ones[Double](x.rows, 1) val x_test = BDM.horzcat(ones, x) val predictions = argmax(x_test * weights, Axis._1) predictions }
# -*- coding: utf-8 -*- """ Created on Wed Feb 12 11:58:06 2020 @author: lixin """
import numpy as np from sklearn import datasets import os import sys sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) from utils import train_test_split, accuracy_score from utils import Plot