Recurrent Neural Networks (RNN)
A recurrent neural network (RNN) is a type of neural network that has been succesful in modelling sequential data, e.g. language, speech, protein sequences, etc.
A RNN performs its computations in a cyclic manner, where the same computation is applied to every sample of a given sequence.
The idea is that the network should be able to use the previous computations as some form of memory and apply this to future computations.
An image may best explain how this is to be understood,
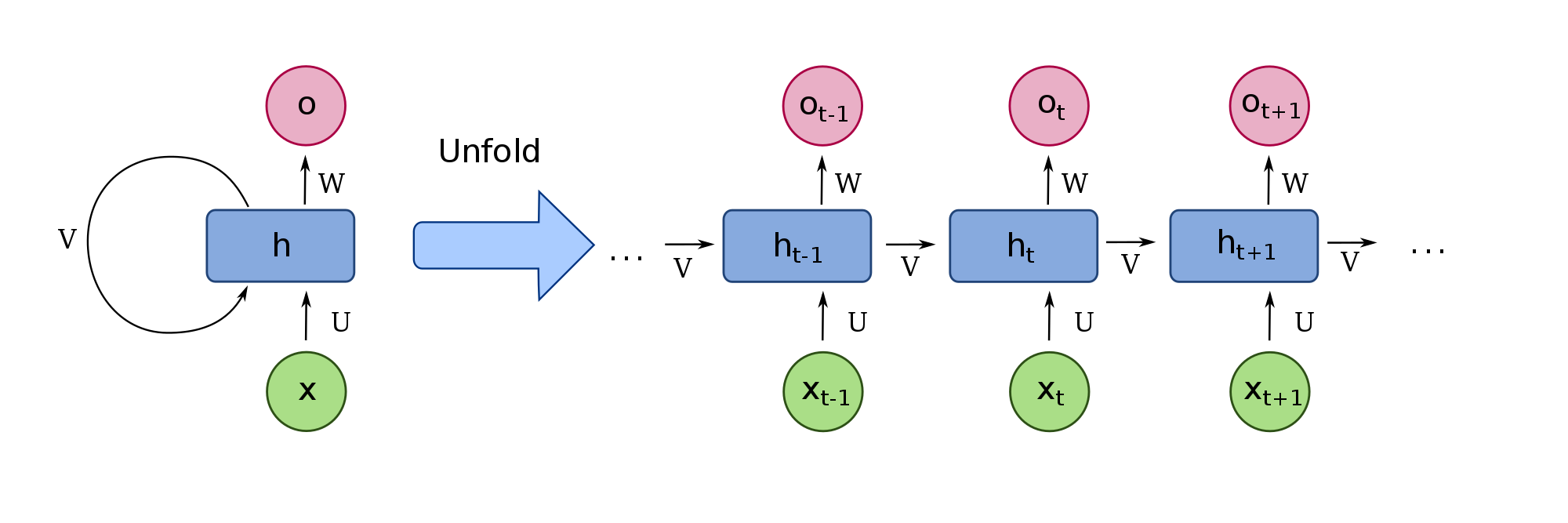
where it the network contains the following elements:
- $x$ is the input sequence of samples,
- $U$ is a weight matrix applied to the given input sample,
- $V$ is a weight matrix used for the recurrent computation in order to pass memory along the sequence,
- $W$ is a weight matrix used to compute the output of the every timestep (given that every timestep requires an output),
- $h$ is the hidden state (the network’s memory) for a given time step, and
- $o$ is the resulting output.
When the network is unrolled as shown, it is easier to refer to a timestep, $t$.
We have the following computations through the network:
- $h_t = f(U\,{x_t} + V\,{h_{t-1}})$, where $f$ is a non-linear activation function, e.g. $\mathrm{tanh}$.
- $o_t = W\,{h_t}$
When we are doing language modelling using a cross-entropy loss, we additionally apply the softmax function to the output $o_{t}$:
- $\hat{y}_t = \mathrm{softmax}(o_{t})$
Long Short-term Memory
The LSTM cell contains three gates, input, forget, output gates and a memory cell.
The output of the LSTM unit is computed with the following functions, where $\sigma = \mathrm{softmax}$.
We have input gate $i$, forget gate $f$, and output gate $o$ defines as
$i = \sigma ( W^i [h_{t-1}, x_t])$
$f = \sigma ( W^f [h_{t-1},x_t])$
$o = \sigma ( W^o [h_{t-1},x_t])$
where $W^i, W^f, W^o$ are weight matrices applied to a concatenated $h_{t-1}$ (hidden state vector) and $x_t$ (input vector) for each respective gate.
$h_{t-1}$, from the previous time step along with the current input $x_t$ are used to compute the a candidate $g$
- $\tilde c_{t} = \mathrm{tanh}( W^g [h_{t-1}, x_t])$
The value of the cell’s memory, $c_t$, is updated as
- $c_t = f \circ c_{t-1} + i \circ\tilde c_{t} $
where $c_{t-1}$ is the previous memory, and $\circ$ refers to element-wise multiplication.
The output, $h_t$, is computed as
- $h_t = \mathrm{tanh}(c_t) \circ o$
and it is used for both the timestep’s output and the next timestep, whereas $c_t$ is exclusively sent to the next timestep.
This makes $c_t$ a memory feature, and is not used directly to compute the output of the timestep.
Forward pass

Operation $z$ is the concatenation of $x$ and $h_{t-1}$
Concatenation of $h_{t-1}$ and $x_t$
LSTM functions
Logits
Softmax
$\hat{y_t}$ is y in code and $y_t$ is targets.
Backward pass
Loss
Gradients
- $dC’_t = \frac{\partial L_{t+1}}{\partial C_t}$ and $dh’_t = \frac{\partial L_{t+1}}{\partial h_t}$
- $dC_t = \frac{\partial L}{\partial C_t} = \frac{\partial L_t}{\partial C_t}$ and $dh_t = \frac{\partial L}{\partial h_t} = \frac{\partial L_{t}}{\partial h_t}$
- All other derivatives are of $L$
targetis target character index $y_t$dh_nextis $dh’_{t}$ (size H x 1)dC_nextis $dC’_{t}$ (size H x 1)C_previs $C_{t-1}$ (size H x 1)- $df’_t$, $di’_t$, $d\bar{C}’_t$, and $do’_t$ are also assigned to
df,di,dC_bar, anddoin the code. - Returns $dh_t$ and $dC_t$
Model parameter gradients
Gated Recurrent Unit
参考: